超文本传输协议(HTTP)快速入门
请求一个页面
这篇文章会用到Curl,Curl是一个用于在命令行中访问URI(Uniform Resource Indicator,统一资源标志符,我们常说的“网址”)的工具。我们用它作为例子,看看一个HTTP客户端如何从服务器获取网页。
在大多数Linux发行版中,这个工具都是默认安装的,你可以在终端模拟器中尝试curl --version:
$ curl --version
curl 7.85.0 (x86_64-redhat-linux-gnu) libcurl/7.85.0 OpenSSL/3.0.8 zlib/1.2.12 brotli/1.0.9 libidn2/2.3.4 libpsl/0.21.1 (+libidn2/2.3.3) libssh/0.10.4/openssl/zlib nghttp2/1.51.0
Release-Date: 2022-08-31
Protocols: dict file ftp ftps gopher gophers http https imap imaps ldap ldaps mqtt pop3 pop3s rtsp scp sftp smb smbs smtp smtps telnet tftp
Features: alt-svc AsynchDNS brotli GSS-API HSTS HTTP2 HTTPS-proxy IDN IPv6 Kerberos Largefile libz NTLM NTLM_WB PSL SPNEGO SSL threadsafe TLS-SRP UnixSockets如果你的系统已经安装了Curl,就会出现和上面类似的输出,而不是一条“找不到”的报错。
如果你使用Windows,Windows 10和Windows 11已经预装Curl。但是在PowerShell的默认环境下,使用curl不会使用curl,你需要用curl.exe来代替接下来所有命令中的curl。(提示:如果你的命令窗口标题有PowerShell字样,说明你可能正在使用PowerShell)
你可以在命令行窗口中尝试curl --version:
> curl.exe --version
curl 7.79.1 (Windows) libcurl/7.79.1 Schannel
Release-Date: 2021-09-22
Protocols: dict file ftp ftps http https imap imaps pop3 pop3s smtp smtps telnet tftp
Features: AsynchDNS HSTS IPv6 Kerberos Largefile NTLM SPNEGO SSL SSPI UnixSockets如果你正在使用没有预装Curl的Windows,你可以在 curl.se/windows/ 下载。
确认Curl可以使用,我们来试试访问http://example.com
$ curl --http1.1 http://example.com -v
* Trying 93.184.216.34:80...
* Trying 2606:2800:220:1:248:1893:25c8:1946:80...
* Immediate connect fail for 2606:2800:220:1:248:1893:25c8:1946: 网络不可达
* Connected to example.com (93.184.216.34) port 80 (#0)
> GET / HTTP/1.1
> Host: example.com
> User-Agent: curl/7.85.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Age: 106060
< Cache-Control: max-age=604800
< Content-Type: text/html; charset=UTF-8
< Date: Sat, 18 Mar 2023 06:39:37 GMT
< Etag: "3147526947+ident"
< Expires: Sat, 25 Mar 2023 06:39:37 GMT
< Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
< Server: ECS (sab/5707)
< Vary: Accept-Encoding
< X-Cache: HIT
< Content-Length: 1256
<
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
* Connection #0 to host example.com left intact在我们使用curl时,我们加上了两个额外参数,一个是--http1.1,一个是-v。--http1.1告诉Curl,我们要求它使用1.1版本的HTTP,否则Curl可能会自动选择其它版本的HTTP;-v则让Curl展示更详细一点的信息,包括连接服务器和HTTP请求。
让我们来关注<!doctype html>之前以<或>开头的行:
> GET / HTTP/1.1
> Host: example.com
> User-Agent: curl/7.85.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Age: 106060
< Cache-Control: max-age=604800
< Content-Type: text/html; charset=UTF-8
< Date: Sat, 18 Mar 2023 06:39:37 GMT
< Etag: "3147526947+ident"
< Expires: Sat, 25 Mar 2023 06:39:37 GMT
< Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
< Server: ECS (sab/5707)
< Vary: Accept-Encoding
< X-Cache: HIT
< Content-Length: 1256
< 在这里,>的意思是发送到服务器,<是从服务器接收。我们向服务器发送的是“请求”(Request),而服务器向我们返回“响应”(Response),一次请求-响应是一次“事务”(Transcation)。Curl执行我们对于example.com的请求,首先向服务器发送了以下信息:
GET / HTTP/1.1
^^^ ~~~~~~~~~~~~ 请求方法 (Request Method)
^ ~~~~~~~~~~ 路径(Path)
^^^^^^^^ ~ 协议(Protocol)这一行可以很容易用大白话说明:“使用HTTP/1.1协议获取(GET)路径‘/’”。
接下来这一段通常被叫作“HTTP头”:
Host: example.com
User-Agent: curl/7.85.0
Accept: */*每一行意味着一个键值对,用Key: Value的格式。Host: example.com告诉服务器我们想请求的域名是example.com,其它两个头我们留到稍后再了解。
这些“HTTP头”跟第一行加起来组成了“HTTP请求头部”的数据。但是还没完,这里还有一个空行:
它标志着“HTTP请求头部”的结束。
另外,还有一个要注意的地方:HTTP的换行是CRLF格式,也就是大多数编程语言中的\r\n字符串转义,这个稍后我们自己编写HTTP服务器的时候才会变得重要。
我们接着来看看服务器发回给我们的数据,它跟请求有两点不同,第一个是:
HTTP/1.1 200 OK
^^^^^^^^ ~~~~~~~~~~ 协议
^^^ ~~~~~~ 状态码(Status Code)
^^ ~~~ 状态信息通常,状态码和状态信息一一对应,或者说,状态信息只是在解释状态码。在这里,200可以说是“成功”的意思。
第二个是,它在空行之后,即”HTTP响应头部“结束之后,带上了我们请求的页面/:
<!doctype html>
<html>
...如果你的电脑上有telnet,你可以亲手发送一个HTTP请求!执行telnet example.com 80来连接到服务器的80端口。
$ telnet example.com 80
Trying 93.184.216.34...
Connected to example.com.
Escape character is '^]'.输入以下内容。就是上面HTTP请求的简化版,HTTP头只留下Host。
GET / HTTP/1.1
Host: example.com
别忘了空行!不必担心换行格式,telnet默认发送CRLF形式的换行,这跟HTTP的要求是一样的。
用词约定
套接字和Socket
Socket是一种对于网络逻辑接口的抽象,本文使用Socket一词。在有些资料中这个词被翻译成“套接字”。
HTTP头部、头
为了尊重使用习惯,本文中的HTTP头和HTTP头部所指的内容是不一样的。为了方便理解,假设有这样的HTTP请求:
GET /path/to/page HTTP/1.1
Host: example.com
User-Agent: sample-client/1
HTTP头部指的是结束标志(空行)以及之前所有部分,而HTTP头指的是第一行之后、结束标志之前的键值对部分。
TCP
本文中的TCP是Transmission Control Protocol的缩写,中文翻译是“传输控制协议”。
从零开始的HTTP服务器生涯
我们已经了解HTTP请求和响应的结构,从这里开始,我们将使用Python来编写一个简单的HTTP服务器。如果你不会Python,可以看看Python文档网站上的教程。我们只会使用许多编程语言都具备的概念和特性,用其它编程语言实现应该也不会有太大障碍。
另外提一句,所有代码都在Fedora 37上使用Python 3.11测试,但是程序并没有使用特殊的特性,在其它平台和Python上多半也能正常使用。
你可能没有从零开始写HTTP服务器的经验,让我来为我们将要完成的代码划分几个部分:
- 监听网络端口,等待连接
- 从连接读取HTTP请求
- 生成HTTP响应并返回
def main():
pass
if __name__ == "__main__":
main()等待客户端连接
HTTP运行在TCP之上,我们需要打开一个TCP端口,等待客户端创建TCP连接。
我们将使用Python标准库里的socket,这个模块应该已经随着你的Python安装了。没用过Socket API也没关系,我将对我们要进行的操作做一个简单介绍。要在一个端口上等待客户端连接,我们大概要进行以下工作:
- 创建一个Socket(使用socket库里的
socket类),配置使用TCP(HTTP在TCP上传输) - 把一个端口bind到这个Socket上(使用Socket的
bind方法) - 将这个Socket设置为监听(使用Socket的
listen方法)
完成这些工作后,我们就可以使用Socket的accept方法等待一个连接。
在main里添加代码之后:
from socket import socket, AF_INET, SOCK_STREAM # 导入我们需要的值
def main():
# SOCK_STREAM配合AF_INET就是在IPv4上使用TCP的意思,HTTP在TCP上传输
with socket(AF_INET, SOCK_STREAM) as server_port: # with会在运行离开这块代码之后关闭这个Socket
server_port.bind(("127.0.0.1", 8989)) # 将127.0.0.1:8989这个地址绑定到这个Socket上
server_port.listen() # 设置监听
conn, addr = server_port.accept() # conn是相应连接的Socket, addr是地址要实验我们的代码是否有效,我们可以编写一个供telnet使用的Echo服务器。Echo服务器,回声服务器,顾名思义就是一个原样输出收到内容的服务器。以下是包含了这个Echo服务器逻辑的文件内容。
from socket import socket, AF_INET, SOCK_STREAM
def main():
with socket(AF_INET, SOCK_STREAM) as server_port:
server_port.bind(("127.0.0.1", 8989))
server_port.listen()
conn, addr = server_port.accept()
with conn: # 运行离开这个with代码块时,with会帮我们关闭这个Socket
print(f"Accepted {addr}")
conn.settimeout(8)
while True:
data = conn.recv(4096) # 接收最多4096 bytes的数据
if data != b"\r\n": # 如果是一个空行(只包含CRLF换行),就退出循环
conn.send(data)
else:
break
if __name__ == "__main__":
main()假设这个Python脚本的名字叫作server.py,我们执行python server.py(因为需要Python 3,有些机器可能要使用python3代替python)。
python server.py
现在我们可以使用telnet localhost 8989连接到我们的Echo服务器。输入一些内容、换行,看看服务器返回的内容。最后用空行退出。
$ telnet localhost 8989
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hello!
Hello!
Connection closed by foreign host.读取HTTP请求
先让我们来总结一下我们之前了解到的内容:一次HTTP事务包括请求和响应,请求和响应发送的数据叫作HTTP信息(Message)。
一个信息包括两部分:头部和主体,一个空行代表头部结束。HTTP请求和响应的头部只有第一行的格式不同,第一行之后都是由键值对组成的HTTP头。
让我们新添加两个函数,分别用于读取HTTP请求和处理HTTP请求:
def read_http_request(conn):
pass
def handle_http_request(conn):
pass HTTP在TCP连接上传输,TCP提供面向字节流传输,意思是:在同一个Socket上,无论你如何发送数据,TCP都将它们视为同一串数据,不保证它们分开到达目标(你可以试试搜索“TCP粘包问题”,这是一个存在又不存在的问题)。当然,TCP保证数据收到的顺序和发送的顺序一致。这也可以帮助你理解HTTP为何要如此设计。
为了简化代码,我们这里将使用比较简单的方法读取HTTP请求,并将其处理成三个返回值:请求方法、路径、头。请求方法和路径是字符串,头是一个Python字典(dict),保存HTTP头键值对。跟Python字典类似功能的东西,在其它编程语言中可能更习惯叫”Map”。
读取HTTP请求时,我们先原样读取出整个头部,存为字符串再解析。读取头部的函数命名为read_http_request_header_string。
def read_http_request_header_string(conn: socket):
buffer = bytearray()
while True:
buffer.extend(conn.recv(4096))
header_length = buffer.find(b"\r\n\r\n") # 两个连在一起的CRLF,第二个CRLF就代表空行
if header_length != -1:
return buffer[:header_length]这样我们就可以在read_http_request里使用它了,你可以先试着写一写这个read_http_request再看完整代码。
逻辑很简单,将读到的字符串按照\r\n分开,再分别处理第一行和剩余的行。需要注意的是,我们的read_http_request_header_string返回bytes(可以简单理解为一块内存),你需要用decode方法将其转换为字符串,该方法需要指定一个编码,你可以使用"ascii"。
def read_http_request(conn: socket):
s = read_http_request_header_string(conn).decode("ascii")
lines = s.split("\r\n") # 按CRLF切开
# 解析第一行
fstline = lines[0]
method, path, protocol = fstline.split(" ") # 按空格切开第一行
if protocol != "HTTP/1.1":
raise RuntimeError("unknown protocol", protocol)
method = method.lower() # 把方法转换成小写
# 解析头
header = {}
if len(lines) > 1:
for line in lines[1:]:
key, value = line.split(": ")
header[key] = value
return method, path, header生成HTTP响应头部
相对于读取请求,生成响应要简单多了,只需要按照格式拼装信息:
STATUS_MESSAGES = {
200: "OK",
400: "Bad Request",
404: "Not Found",
500: "Server Error",
}
def build_http_response_header(status_code, headers):
lines = [
f"HTTP/1.1 {status_code} {STATUS_MESSAGES[status_code]}"
]
for key, value in headers:
lines.append(f"{key}: {value}")
lines.append("") # 别忘了加空行
lines.append("")
return '\r\n'.join(lines).encode('ascii')请注意,这里为了增加空行,使用两次lines.append("")增加了两个空字符串。因为'\r\n'.join只在两个字符串中间增加分隔符"\r\n"。
举个例子:我们有"A"、"B"两个字符串,每个字符串一行。如果我们不增加空字符串,'\r\n'.join只会在A和B之间插入一个换行,结果是"A\r\nB"。
如果我们只在列表末尾增加一个空字符串,那么最后就只会是
"A\r\nB\r\n"
^ 新增加的空字符串,只是在B和增加的空字符串中间增加了一个换行;如果需要单独的空行,还需要一个额外空字符串,在第一个空字符串和第二个空字符串之间再插入一个换行,才会变为我们需要的"A\r\nB\r\n\r\n"。
处理HTTP请求
接下来我们正式在handle_http_request中处理HTTP请求。首先我们读取HTTP请求,如果请求出错,我们返回400 Bad Request。
def handle_http_request(conn: socket):
try:
method, path, headers = read_http_request(conn)
except Exception as e:
conn.send(build_http_response_header(400, []))
print(f"- - 400 {STATUS_MESSAGES[400]}")
raise e # 把错误重新抛出,方便你看错误堆栈然后我们检查方法是否是get,路径是否是/或者/index.html,满足条件的话我们就返回200 OK和一段HTML内容:
if method == "get" and (path == "/" or path == "/index.html"):
headers = [
("Charset", "UTF-8"),
("Content-Length",str(len(DEFAULT_PAGE_HTML))),
("Connection", "close"),
]
conn.send(build_http_response_header(200, headers))
conn.send(DEFAULT_PAGE_HTML)
print(f"{method.upper()} {path} 200 {STATUS_MESSAGES[200]}")你发现我们在这里设置了三个头,一个是Charset,我们将它设置为UTF-8,这是提示客户端,我们的内容使用UTF-8编码。我们的DEFAULT_PAGE_HTML定义如下:
DEFAULT_PAGE_HTML = """<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Default Page</title>
</head>
<body>
<h1>Hello World!</h1>
</body>
</html>""".encode("utf-8")这里我们使用.encode("utf-8")将字符串转换为bytes。关于decode、encode方法和编解码可以阅读Python文档相应页面。
另一个头是Content-Length,这个头指定了HTTP主体(Body)的长度,也就是我们返回HTML的长度,接收端会根据这个长度读取主体内容。长度必须是十进制的字节数量。你可以看到我们在这里给了DEFAULT_PAGE_HTML的长度。
最后一个是Connection: close,这样设置意味着:无论是客户端还是服务器都可以在响应完成之后关闭相应连接。设置这个头是因为我们的服务器在响应HTTP请求之后就会自动关闭连接,但是HTTP/1.1默认不会关闭。
最后,如果不满足条件,返回404 Not Found,意味着这个页面没有找到。
else:
conn.send(build_http_response_header(404, []))
print(f"{method.upper()} {path} 404 {STATUS_MESSAGES[404]}")最后只要在我们的main函数使用这个handle_http_request就好了。
def main():
with socket(AF_INET, SOCK_STREAM) as server_port:
server_port.bind(("127.0.0.1", 8989))
server_port.listen()
conn, addr = server_port.accept()
with conn:
conn.settimeout(8)
handle_http_request(conn)使用python server.py启动之后,使用curl http://localhost:8989 -v来看看效果。
$ curl http://localhost:8989 -v
* Trying 127.0.0.1:8989...
* Connected to localhost (127.0.0.1) port 8989 (#0)
> GET / HTTP/1.1
> Host: localhost:8989
> User-Agent: curl/7.85.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Charset: UTF-8
< Content-Length: 175
< Connection: close
<
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Default Page</title>
</head>
<body>
<h1>Hello World!</h1>
</body>
* Closing connection 0
</html>⏎我们的代码处理了一个新连接就退出了,如果要让它持续处理新连接,只要从accept方法开始放在死循环里就行:
def main():
with socket(AF_INET, SOCK_STREAM) as server_port:
server_port.bind(("127.0.0.1", 8989))
server_port.listen()
while True:
conn, addr = server_port.accept()
with conn:
conn.settimeout(8)
handle_http_request(conn)使用浏览器开发者工具
浏览器开发者工具是调试你Web程序的利器!它就内置在你的浏览器里,包含多个有用的工具,快捷键通常是F12。接下来,我将演示用Firefox的开发者工具查看我们的服务器响应信息。
先打开一个新标签页。你有两种方法打开开发者工具:一种是在浏览器菜单里点击“更多工具”, 点击“Web开发者工具”。

另一种打开方法是按键盘上的F12。
打开后,你就会看到开发者工具,选择“网络(Network)”页面。
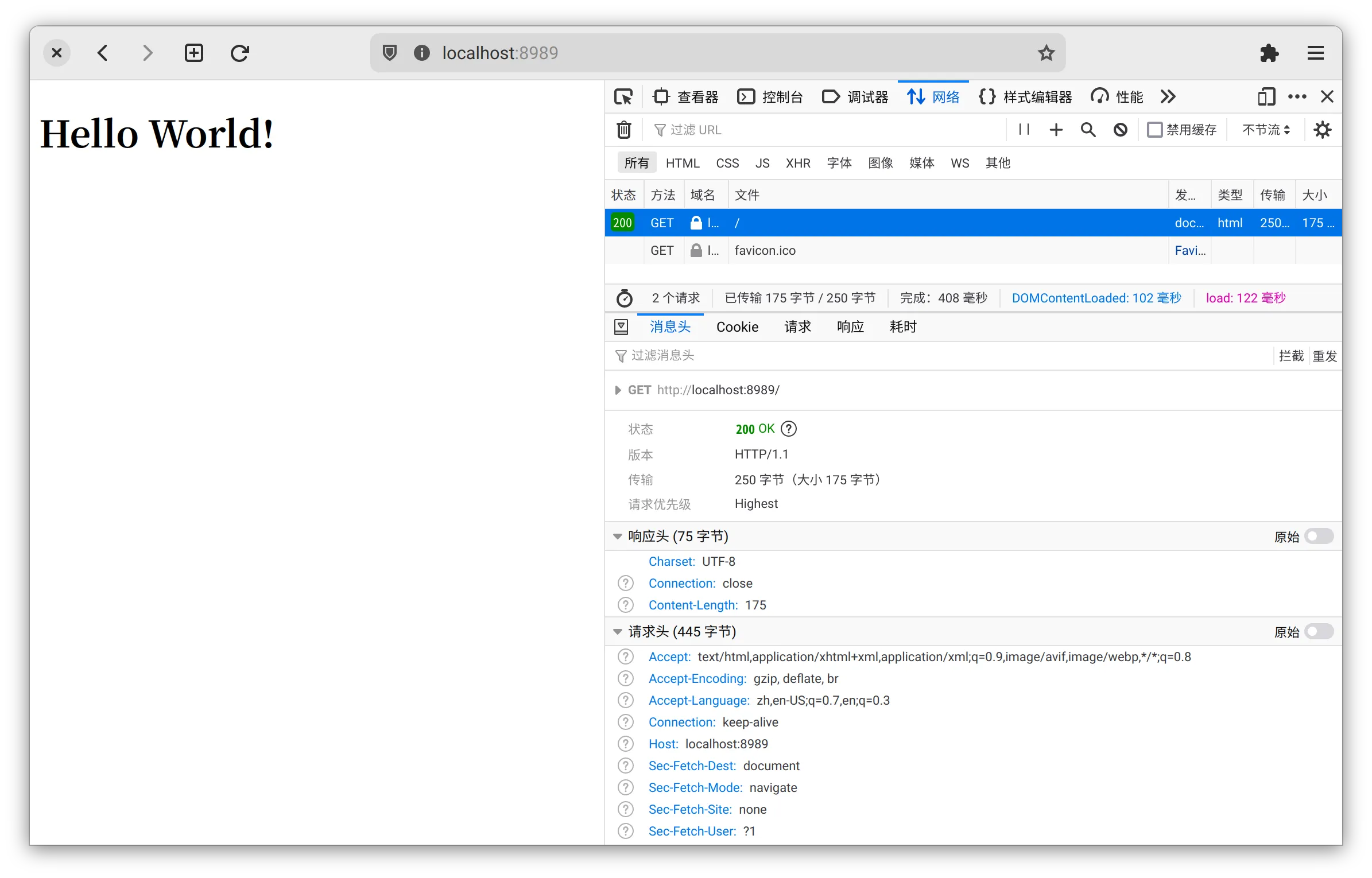
接下来,在地址栏中输入我们服务器的地址http://localhost:8989、确认访问,就可以在这个页面下看到浏览器产生的请求。点击单个项目可以展开详细信息。
GET和POST
我们的服务器应该能够根据用户的输入进行不同的操作,不然为什么不直接提供一个HTML就好了呢?正好,HTTP给我们提供了一个工具:路径里面可以携带一个叫查询(Query)的部分,?之后就是我们的查询,查询里面可以直接携带URI未保留字符,这些字符在URI中没有特殊意义。比如在/?something中,something就是我们的查询。
查询其实是属于URI的一部分。我们在这里说查询是在“路径”中,这里的“路径”指的是前面我们所提到HTTP请求格式中的“路径”。
但是有一些字符不能直接放进URI里,因为它们是URI的保留字符,比如@,这时候就需要转义(Escape)这些字符。我们在这使用的编码叫URL encoding(URL编码,也可以叫percent encoding,百分号编码)。
比如说我们要在路径里携带example@example.com,比如/?email=example@example.com,我们必须将其编码成/?email=example%40example.com。
虽然查询里面可以携带任何允许的字符,但是使用类似上面的格式仍然是比较常用的做法。也就是key=val代表键key的值是val,在上面就是email的值是example@example.com。如果要携带多对键值,可以用&从中间区分,比如email=example%40example.com&nuke=1,就有email和nuke两对键值。
接下来,我们一起改写上面的服务器,让它能够接受查询字符串,比如说在访问/?name=HTTP的时候可以返回”Hello HTTP!“。
在GET请求中接受用户输入
我们要修改以下部分:
- 修改访问路径匹配。我们之前使用
path == "/"来确认正在访问的路径,这样的话/?name=HTTP就不能访问到/了。 - 处理查询里的键值对。我们需要从请求中的路径取得访问路径和查询,将查询里的键值对解析成我们需要的数据结构,在这里是字典。
- 让
DEFAULT_HTML_PAGE的”World”可以自定义。我们在这里使用Python的str.format方法。
首先,我们需要从请求中的路径取得访问路径和查询:
def read_path(path: str): # 返回访问路径和查询
parts = path.split("?", maxsplit=1)
if len(parts) > 1:
return parts[0], parts[1]
else:
return parts[0], ""
def handle_http_request(conn: socket):
# ...
onlypath, query = read_path(path)
if onlypath == "/" and method == "get":
# ...然后,我们需要将查询里的键值对解析成字典:
def parse_query(q: str):
pairs_str = q.split("&")
pairs = {}
for s in pairs_str:
if s: # 确保不是空字符串
k, v = s.split("=")
pairs[unquote_plus(k)] = unquote_plus(v)
return pairs在这里,我们使用了urllib.parse的unquote_plus函数,你需要在文件顶部引入它:
from urllib.parse import unquote_plus我们使用这个函数将URL编码的字符串转换为普通字符串。
接下来,我们要让DEFAULT_HTML_PAGE可以接受自定义名字。因为bytes对象没有format方法,我们得去掉.encode,改在自定义名字之后完成。
DEFAULT_PAGE_HTML = """<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Default Page</title>
</head>
<body>
<h1>Hello {name}!</h1>
</body>
</html>"""当我们使用format方法时,就可以替换掉{name}的内容,生成实际要发送给客户端的页面。这时DEFAULT_PAGE_HTML就被叫作“模板”,生成这个页面的过程叫“渲染”。
if onlypath == "/" and method == "get":
query_dict = parse_query(query) # 解析查询键值对
# 渲染页面
content = DEFAULT_PAGE_HTML.format(
# 检查键值对中有没有键name,有并且值不为空的话就以其值替换{name},否则用World替换。
name=(query_dict["name"] if query_dict.get("name") else "World")
).encode("utf-8")
headers = [
("Charset", "UTF-8"),
("Content-Length",str(len(content))), # 主体长度等于实际内容长度
("Connection", "close"),
]
conn.send(build_http_response_header(200, headers))
conn.send(content) # 发送渲染出来的页面
# ...启动你的服务器。用curl http://localhost:8989?name=HTTP -v试试。
$ curl http://localhost:8989?name=HTTP -v
* Trying 127.0.0.1:8989...
* Connected to localhost (127.0.0.1) port 8989 (#0)
> GET /?name=HTTP HTTP/1.1
> Host: localhost:8989
> User-Agent: curl/7.85.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Charset: UTF-8
< Content-Length: 174
< Connection: close
<
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Default Page</title>
</head>
<body>
<h1>Hello HTTP!</h1>
</body>
* Closing connection 0
</html>⏎你也可以用浏览器看看。修改一下name的值,看看给出什么结果。如果出现bug,尝试自己修一修。
修改一下模板,就可以直接在网页里面使用这个参数了。
DEFAULT_PAGE_HTML = """<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Default Page</title>
</head>
<body>
<h1>Hello {name}!</h1>
<form method="GET">
<input name="name" label="Hello to..." />
<button type="submit">Submit</button>
</form>
</body>
</html>"""HTML不在本文范围,敬请参阅MDN Web Docs相关页面。
HTTP POST
目前为止,我们都在使用HTTP的GET方法。另一个常用的HTTP方法是POST,为什么我们需要它呢?
- HTTP请求可以跟响应一样携带主体。GET请求不可以携带主体,但POST请求可以。放在路径里的数据经过编码后体积可能大幅增加;主体里的数据格式并没有规定,可以不用编码。
- 理论上HTTP请求头部的路径可以无限长,但是客户端或者服务器可能会限制路径最大长度。
- 在浏览器中,路径会被记录在浏览历史里,放在主体里的数据一般不会被记录。
如果我们使用HTML的form元素进行请求,POST请求主体使用的格式与我们之前查询键值对的格式相同。键是form元素内input元素name属性的值。
绝大部分情况下,你应该用GET方法展示数据、POST方法只用来记录数据。在刷新POST方法返回的页面时,浏览器需要重新提交请求,并会询问用户是否要这样做(因为这样做可能会导致不需要的副作用)。大部分情况下,这不是用户想体验的麻烦。 如果你使用HTML的form直接处理POST提交,你可以在处理POST方法完成后返回HTTP 303 See Other状态码并在
Location头中指定重新请求的地址,让浏览器用GET方法重新请求并展示相应页面。 我们接下来就是采用类似方法。
让我们来改写我们之前的服务器,让它可以接受POST方法的default_name参数,并将它设置为默认名字(当没有name参数时使用的名字)。
先添加一个全局变量:
global default_name
default_name = "World"这是个比较大的改写,首先我们要先改写读取HTTP请求的部分,让它支持读取主体。然后我们要使用一个全局变量保存我们对默认名字的修改。
def read_http_request_header_string(conn: socket):
buffer = bytearray()
while True:
buffer.extend(conn.recv(4096))
header_length = buffer.find(b"\r\n\r\n")
if header_length != -1:
return buffer[:header_length], buffer[header_length+4:]
def read_http_request(conn: socket):
s, rest = read_http_request_header_string(conn)
s = s.decode("ascii")
lines = s.split("\r\n")
# 解析第一行
fstline = lines[0]
method, path, protocol = fstline.split(" ")
if protocol != "HTTP/1.1":
raise RuntimeError("unknown protocol", protocol)
method = method.lower()
# 解析头
header = {}
if len(lines) > 1:
for line in lines[1:]:
key, value = line.split(": ")
header[key] = value
return method, path, header, rest
def read_http_request_body(conn: socket, length: int, buffer: bytearray):
while len(buffer) < length:
buffer.extend(conn.recv(4096))
return buffer[:length]我们在原先read_http_request函数的基础上增加read_http_request_body,并且让read_http_request返回多读的数据(在\r\n\r\n之后的数据)。在handle_http_request,我们这样读取主体:
def handle_http_request(conn: socket):
global default_name
try:
method, path, headers, rest = read_http_request(conn)
if "Content-Length" in headers:
body = read_http_request_body(conn, int(headers["Content-Length"]), rest)
# 我们在这只支持Content-Length,不支持Transfer-Encoding: chunked
else:
body = bytearray()
except Exception as e:
conn.send(build_http_response_header(400, []))
print(f"- - 400 {STATUS_MESSAGES[400]}")
raise e
# ...接下来我们要改动检查路径和方法的代码:
onlypath, query = read_path(path)
if onlypath == "/":
if method == "get":
query_dict = parse_query(query)
# 渲染页面
content = DEFAULT_PAGE_HTML.format(
name=(query_dict["name"] if query_dict.get("name") else default_name)
# 这里引用全局变量default_name的值,而不是硬编码"World"
).encode("utf-8")
headers = [
("Charset", "UTF-8"),
("Content-Length",str(len(content))),
("Connection", "close"),
]
conn.send(build_http_response_header(200, headers))
conn.send(content)
print(f"{method.upper()} {path} 200 {STATUS_MESSAGES[200]}")
return # 响应完成,直接返回
elif method == "post": # 处理POST请求
form_data_s = body.decode("utf-8")
form_dict = parse_query(form_data_s)
if form_dict.get("default_name"):
default_name = form_dict["default_name"]
conn.send(build_http_response_header(303, [
("Connection", "close"),
("Location", "."),
])) # 让浏览器重新用GET请求并展示当前页面,Location是“.”
print(f"{method.upper()} {path} 303 {STATUS_MESSAGES[303]}")
return # 响应完成,直接返回
conn.send(build_http_response_header(404, [])) # 没有匹配的路径或者方法,返回404
print(f"{method.upper()} {path} 404 {STATUS_MESSAGES[404]}")最后,改动一下模板,这样我们就可以直接使用这个参数了:
DEFAULT_PAGE_HTML = """<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Default Page</title>
</head>
<body>
<h1>Hello {name}!</h1>
<form method="GET">
<input name="name"/>
<button type="submit">Submit</button>
</form>
<h2>Default Name</h2>
<form method="POST">
<input name="default_name" />
<button type="submit">Submit</button>
</form>
</body>
</html>"""再进一步
我们的代码尚不完善,你可以试试按以下方向改进。
-
处理并发连接
当前的代码只能依照顺序一个一个处理连接,你使用多线程或者Python的asyncio让我们的服务器能够并发处理连接。
参考资料:
-
连接复用
当前代码在回应请求之后就直接关闭连接,你可以支持HTTP/1.1式的连接复用来提高连接使用效率。
参考资料:
-
增强兼容性
我们目前的代码作了一些假设,你可以改进代码以提高对不同客户端的兼容性。
- 支持HTTP Transfer-Encoding,我们的代码中没有支持这种传输方式
-
包装和抽象
你可以将HTTP服务器包装起来,甚至进一步包装成可以使用的框架,为用户提供可用的API。例如:
from mymodule import MyServer def handle_index(request): return request.ok(template="index.html") if __name__ == "__main__": server = MyServer({ "/": handle_index }) server.run()你还可以试试阅读Tornado的代码,这是一个Python异步Web框架。
-
支持Cookie
HTTP是一个无状态协议:不同的响应-请求之间没有联系。HTTP Cookie是一项在不同响应-请求之间保留数据的技术。设计一个需要保留数据的功能,并在我们的HTTP服务器中实现它。
参考资料:
参考资料和扩展阅读
本文内容主要基于HTTP/1.1。如今,HTTP已经改进出HTTP/2和HTTP/3。这些新版本协议更加高效,更加适合我们当下的使用场景。虽然HTTP/2和HTTP/3与HTTP/1.1相比变化很大,但是基本概念并没有什么变动。